Earlier today I experimented with analyzing my delicious links to determine my favourite interests. I created a Ruby script called
interspicious to do this.
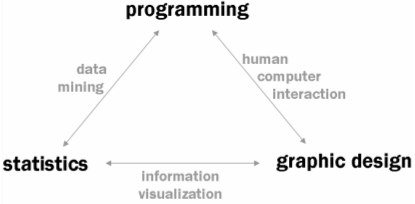
I was hoping that the script would tell me my 5 or 6 favourite areas of interest, but the results are too granular -- many topics identified belong to the same space:

I did use the
Porter Stemming Algorithm to combine similar tags by dropping their suffixes, but I see that I'm going to need to cluster the tags by
meaning, not just by their etymology.
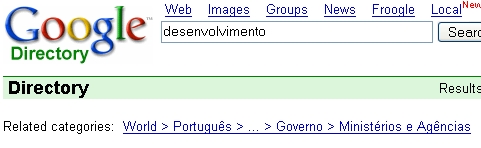
And I think I know how -- Google Directory:

Note that Google Directory does some very nice clustering in its "Related Categories" section. So I'm going to write a script to scrape this information to cluster the hundreds of results from
interspicious. Hopefully, hopefully, the result of all this will be a machine-generated list of my favourite interests!
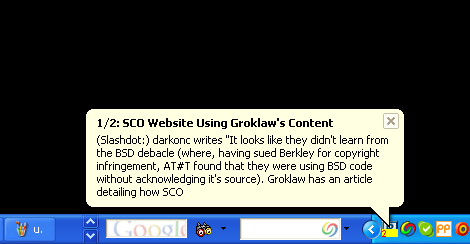
OK, here's interspicious2 in action:

Here it is analyzing my link "RPA-base: GoodAPIDesign". It finds all the tags that others have applied to this link. It then retrieves the set of categories for each tag by scraping Google Directory. (Any tags that have previously been used for scraping are cached, for efficiency).
At the bottom of the screen you can see the categories found for the tags. Some are pretty good ("Languages/Ruby"). Others are not so good ("Health/Alternative"). But the noise will be significantly reduced as we process hundreds more of these links. At the end we will have an accurate list of categories describing the person's favourite interests, which is the goal of the script.
OK, here is the script, introspicious2, written in Ruby. It analyzes your del.icio.us links to find the tags describing your favourite interests, and clusters those tags into meaningful categories using Google Directory:
# This Ruby script analyzes your del.icio.us links to determine your
# favourite interests by listing the tag categories that are most
# frequently used. Because you may not tag your links, this script
# uses the tags from *all* users, for *your* links.
#
# The result is a list of tag categories, sorted by the number of
# links that *you* have associated with each. In effect, you get a
# description of your favourite interests, starting with the ones you
# enjoy the most. It is a means of introspection, using the
# descriptive power of delicious tags. Hence the name of the script:
# introspicious.
#
# Technical Note: To find the categories associated with a given tag,
# this script looks up the tag in Google Directory to see what
# categories it is under.
#
# Instructions:
# 1. Save this script as "introspicious.rb"
# 2. Edit it to use your del.icio.us username and password
# 3. Download and install Ruby
# 4. Run this script using "ruby introspicious.rb"
#
# (Would someone be willing to write a web front-end for this script,
# so that it is more accessible to others?)
#
# [Jon Aquino 2005-03-06]
$delicious_username = 'JonathanAquino'
$delicious_password = 'tiger'
require 'net/http'
def printException(e)
# Force Ruby to print the full stack trace. [Jon Aquino 2005-03-07]
puts "Exception: #{e.class}: #{e.message}\n\t#{e.backtrace.join("\n\t")}"
end
class Link
attr_accessor :url, :description, :checksum
def initialize(url, description, checksum)
@url = url
@description = description
@checksum = checksum
end
end
class Delicious
def all_links
last_url = nil
last_description = nil
all_links = []
# Change "all" to "recent" for a quicker test [Jon Aquino 2005-03-07]
get('/api/posts/all').each {|line|
if line =~ /href="([^"]+)"/
last_url = $1
end
if line =~ /description="([^"]+)"/
last_description = $1
end
if line =~ /hash="([^"]+)"/
all_links << Link.new(last_url, last_description, $1)
end
}
all_links
end
def tags(link)
tags = []
get('/url/'+link.checksum).each {|line|
next if not line =~ /^\s*<.*delNav.*>(.*)</
tags << $1
}
tags.uniq
end
def get(path)
# Wait 1 second between queries, as per
# http://del.icio.us/doc/api [Jon Aquino 2005-03-06]
sleep 1
response = nil
Net::HTTP.start('del.icio.us') { |http|
req = Net::HTTP::Get.new(path)
req.basic_auth $delicious_username, $delicious_password
response = http.request(req).body
}
response
end
end
# Version 1 of this script used the Porter Stemming Algorithm to
# cluster tags etymologically. The current script scrapes Google
# Directory to cluster tags semantically. [Jon Aquino 2005-03-06]
class GoogleDirectory
def initialize
@query_to_cached_categories_map = {}
end
def categories(query)
if @query_to_cached_categories_map.keys.include? query
puts "(Cached: #{query})"
else
attempts = 1
begin
@query_to_cached_categories_map[query] = categories_proper(query)
rescue Exception => e
# Sometimes I get c:/ruby/lib/ruby/1.8/timeout.rb:42:in
# `rbuf_fill': execution expired (Timeout::Error).
# [Jon Aquino 2005-03-07]
printException(e)
puts "(Retrying)"
attempts += 1
retry if attempts <= 5
end
end
@query_to_cached_categories_map[query]
end
def categories_proper(query)
response = Net::HTTP.get("www.google.com", "/search?q=#{query}&cat=gwd%2FTop")
response.gsub!(/\n/, " ")
response.gsub!(/Related categories:/, "$$$Related categories:")
response.gsub!(/<\/table>/, "</table>$$$")
response.split("$$$").each { |line|
break if line =~ /Related categories:(.*)<\/table>/
}
line = $1
return [] if line == nil
line.gsub!(/href=/, "$$$")
line.gsub!(/\/>/, "$$$")
categories = []
line.split("$$$").each { |substring|
next if not substring =~ /http:\/\/directory.google.com\/Top\/([^?]+)/
categories << $1
}
categories.uniq
end
private :categories_proper
end
delicious = Delicious.new
google_directory = GoogleDirectory.new
categories = []
begin
i = 0
delicious.all_links.each { |link|
i += 1
puts "\n#{i}. #{link.description}\n#{link.url}"
tags_for_link = delicious.tags(link)
puts "Tags: #{tags_for_link.join(", ")}"
categories_for_link = []
tags_for_link.each { |tag|
categories_for_link += google_directory.categories(tag)
}
categories_for_link.uniq!
puts "Categories: #{categories_for_link.join(", ")}"
categories += categories_for_link
}
rescue Exception => e
printException(e)
exit 1
end
class CategoryCount
attr_reader :category, :count
def initialize(category)
@category = category
@count = 0
end
def inc
@count += 1
end
end
category_to_categorycount_map = Hash.new
categories.uniq.each { |category| category_to_categorycount_map[category] = CategoryCount.new(category) }
categories.each { |category| category_to_categorycount_map[category].inc }
category_to_categorycount_map.values.sort { |a,b| b.count <=> a.count }.each { |categorycount|
puts "#{categorycount.count} page#{categorycount.count==1?"":"s"} categorized as #{categorycount.category}"
}
And here are the results!

As expected, computer programming tops the list, as it is my #1 interest. But there are some strange categories as well (strange in terms of my interests, that is) - "Economics/Development", "Sterling,_Bruce", "University_of_Illinois". Maybe we need to reduce the granularity a bit...
Here are my results if we collapse all the categories to 1-level deep:
65% - 235 pages categorized as Computers
52% - 188 pages categorized as Arts
50% - 182 pages categorized as Science
45% - 164 pages categorized as Society
43% - 156 pages categorized as Reference
43% - 155 pages categorized as World
41% - 150 pages categorized as Business
33% - 122 pages categorized as Shopping
30% - 108 pages categorized as Kids_and_Teens
29% - 105 pages categorized as Regional
Computers, obviously, are a major interest for me. I have an interest in the Arts, as well as in Science. Meanwhile, the World, Society, and Business are a bit outside my radar screen. This is a fairly accurate picture.
Let's probe 2-levels deep to get a bit more specific:
50% - 180 pages categorized as Computers/Software
45% - 162 pages categorized as Computers/Internet
43% - 157 pages categorized as Computers/Programming
38% - 137 pages categorized as Science/Social_Sciences
28% - 104 pages categorized as Reference/Education
27% - 98 pages categorized as Arts/Music
26% - 95 pages categorized as Computers/Data_Formats
26% - 94 pages categorized as Science/Technology
25% - 92 pages categorized as Arts/Literature
24% - 89 pages categorized as Business/Industries
24% - 88 pages categorized as World/Deutsch
23% - 84 pages categorized as Computers/Multimedia
23% - 84 pages categorized as Society/Religion_and_Spirituality
Computers tops the list, as expected. Not sure where "Science/Social_Sciences" and "Reference/Education" is going -- guess I'll have to prove a few levels deeper to understand that. I don't know what "World/Deutsch" is doing on the list. And I do have an interest in Religion_and_Spirituality, which explains the Society category.
It would be fascinating to make a tree-control that displayed this information -- a tree viewer would be a better way to browse this stuff than straight lists. Hm! It occurs to me that if I converted it to XML, I could just open it in Internet Explorer, which displays XML in a tree format.
In conclusion, del.icio.us tags and Google Directory categories can be used to automatically infer a person's favourite interests based on the web pages they visit. By combining the flat structure of del.icio.us tags with the hierarchical structure of Google Directory categories, we arrive at a tree of the person's interests, with quantitative values for the strength of each interest.
Update: After manually weeding out some of the entries, here is the definitive list of my favourite interests:
26% - 96 pages categorized as Computers/Programming/Languages
16% - 60 pages categorized as Arts/Graphic_Design
16% - 58 pages categorized as Society/Subcultures/Geeks_and_Nerds
15% - 54 pages categorized as Computers/Internet/On_the_Web/Weblogs/Tools
14% - 51 pages categorized as Science/Technology
I love programming, obviously. But I also have a penchant for graphic design. I love the idea of cyberspace and cyberculture, which is where "Subcultures/Geeks_and_Nerds" comes in. I love writing for a large audience on the web ("Weblogs"). And in general, I just love technology.